How to Build a Log Analytics Workbook for Unused CA Policies
How to create a Workbook to see which CA-Policy is used (or not used)
Welcome to my new blog post
Klicke hier, wenn Du lieber in Deutsch lesen möchtest
English version
General
In Entra, you will find several workbooks that provide useful insights into the state of your tenant. They are located in the Entra Admin Center under Monitoring & Health, directly within Workbooks.
A dedicated section is reserved for Conditional Access. Not surprising, CA policies are among the most security-critical configurations in a tenant.
However, the existing workbooks in the Insights section focus on individual perspectives: users, target resources, or identified risks.
As part of my Entra housekeeping activities, I noticed that there is no central workbook that provides an overall view of which policies were successfully applied, which ones blocked access, and which ones may never be triggered at all and therefore could potentially be unnecessary.
That is exactly what I want to address in this article. We will create a simple workbook that provides this overview, which you can then extend based on your own requirements. Along the way, we will also discuss some key elements involved in building workbooks.
If you are not interested in the step-by-step instructions, you can simply download the JSON workbook template and try it out right away. Create a new Workbook and import the JSON from the file.
A workbook offers many possibilities for designing individual elements. Accordingly, the available parameters and configuration options are quite extensive. It would neither be practical nor useful to explain every detail here. Microsoft does that much better in MS Learn.
In the following sections, we will focus on the key elements and their most important properties.
If you would like to build the workbook step by step yourself, also to gain a better understanding of how it works, I recommend creating a new workbook and then importing the JSON template mentioned above.
This way, you will get the fully configured workbook, can edit it, review all parameters and their properties in detail, and at the same time rebuild your own version using the same information to better understand the structure.
Prerequisite: Logs in Log Analytics
If you want to perform evaluations over a longer period of time, the log data must be stored in a Log Analytics workspace.
By default, this is not the case. Entra stores sign-in and audit logs (depending on your license) only for a limited period of time (usually up to 30 days) directly within Entra ID.
If you want to look further back, and that is exactly what we need for housekeeping, you need a place where the logs are stored long term.
A Log Analytics workspace is exactly that: a central storage location for your logs. In addition, it allows you to use KQL to build targeted queries and analyze the data.
Without Log Analytics, historical analysis is very limited. With Log Analytics, it becomes a solid data foundation for governance decisions.
I described how to set this up and how to route the log data there in a previous article.
Take a look here: Zero Trust Monitoring
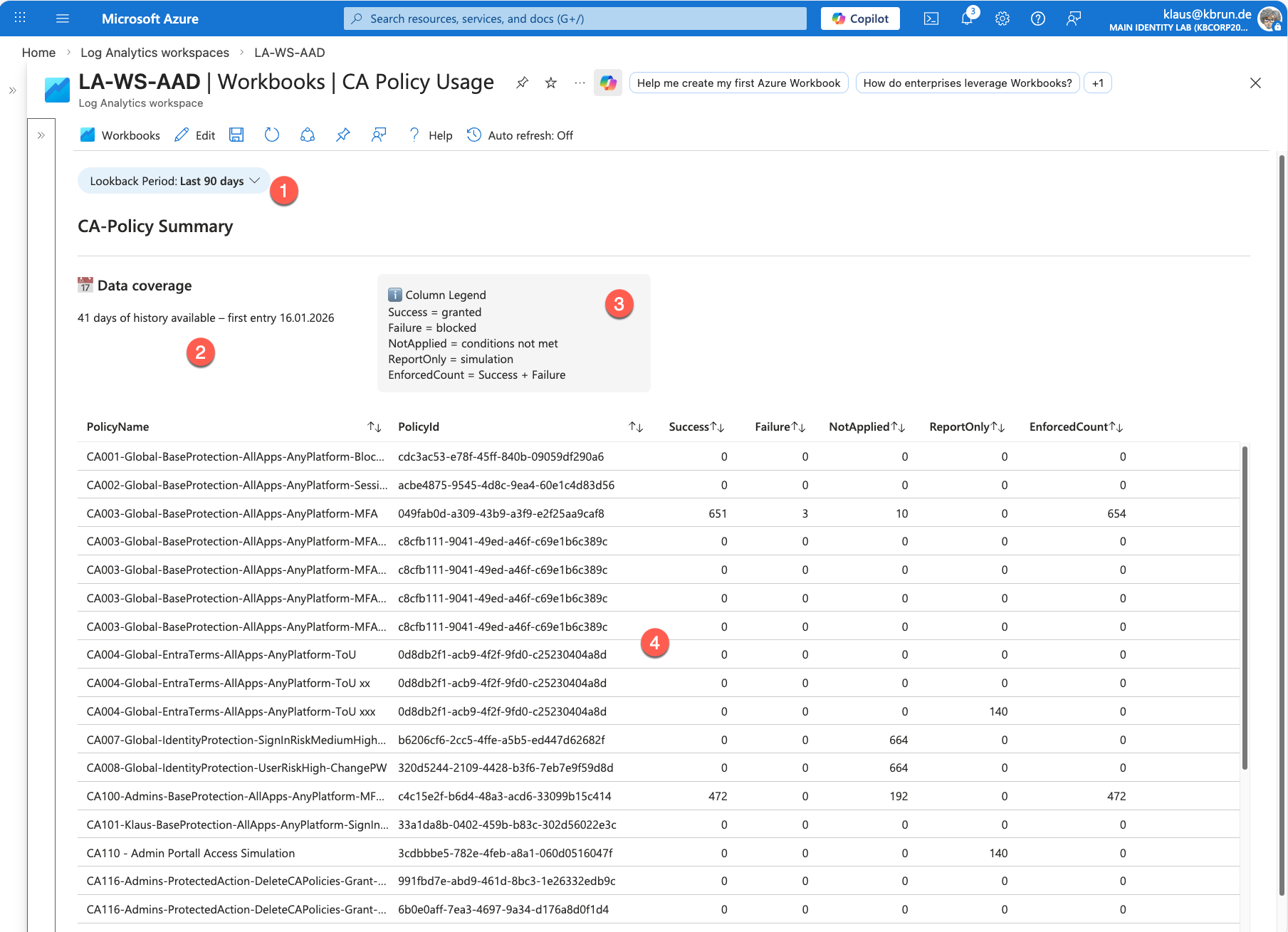
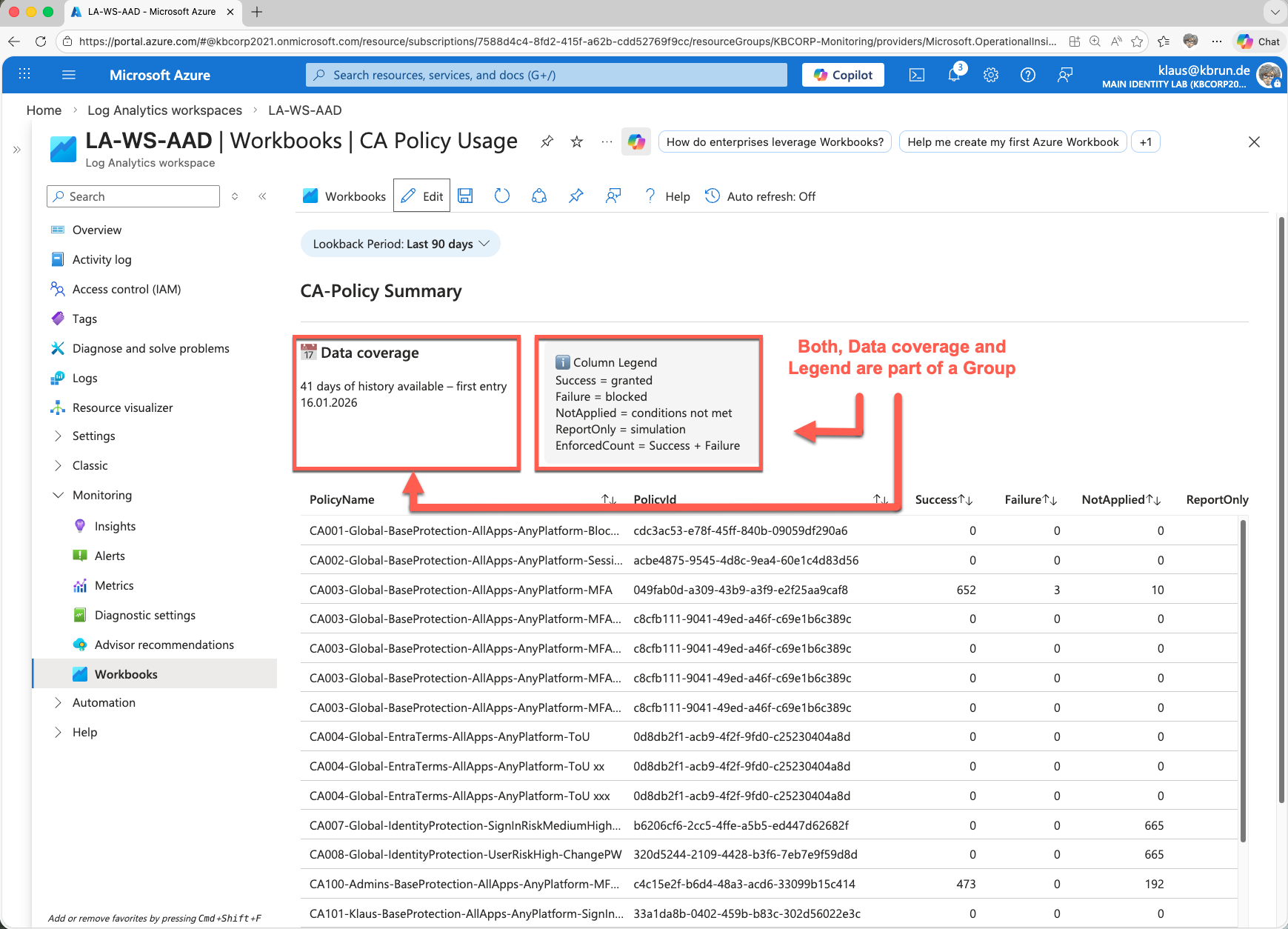
The image above shows the workbook with its individual sections:
Select time range
Here you can choose the desired time period. In the dropdown list, I go back up to 180 days, provided that data is available for that period (retention period).Actual data coverage
This section shows how far back the available data actually goes. This is especially helpful if you do not know the configured retention period in your Log Analytics workspace. In my example, it shows 41 days. That is because I only increased the retention period in the Log Analytics workspace 11 days ago. As a result, older data is currently not available.Legend
A small legend explains the meaning of the individual columns in the workbook.Policy information
Here you see the actual evaluations of the Conditional Access policies. In my test environment, some policies appear multiple times as you can see. This is not a workbook issue. The reason is that I deleted and re-imported several CA policies for testing purposes for my Backup/Restore Conference Session. As a result, historical log data exists in the Log Analytics workspace for different Policy IDs, even if the name is identical. Under normal circumstances in a production environment, this behavior typically does not occur.
Workbook elements in detail
If you have created a new, empty workbook, the first step is to add a new element. In our case, we need a parameter that will later act as kind of a variable within the actual KQL query.
Workbooks consist of different element types, for example text, queries, or parameters. For our use case, we select the element type Parameter, which we can later reference within the KQL query.
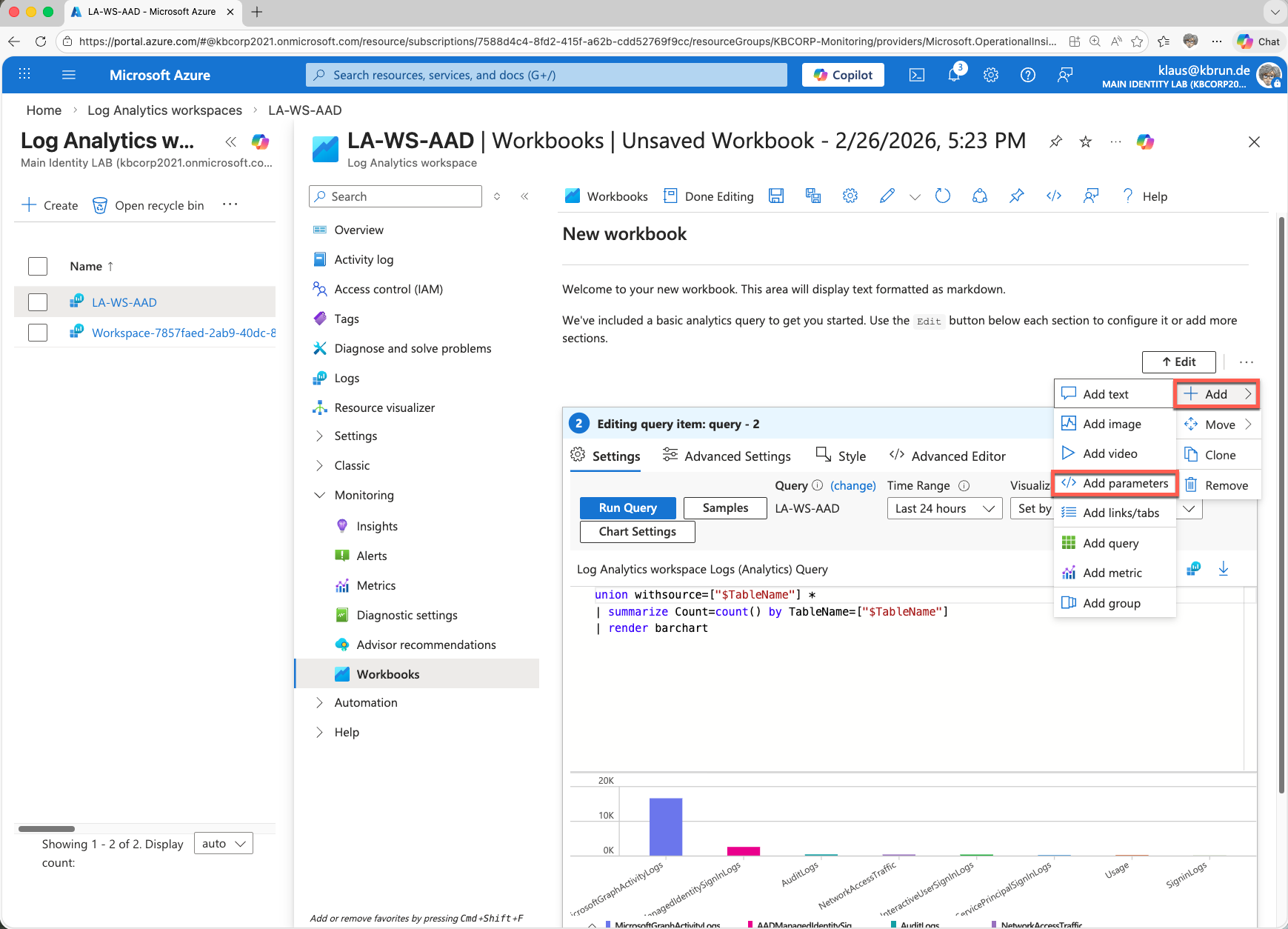
The parameter Lookback Period provides the time range (for example 30, 90, or 180 days), which we then reuse in the query via {timerange}. This keeps the workbook flexible without requiring changes to the query itself.
The finished dropdown definition looks as follows:
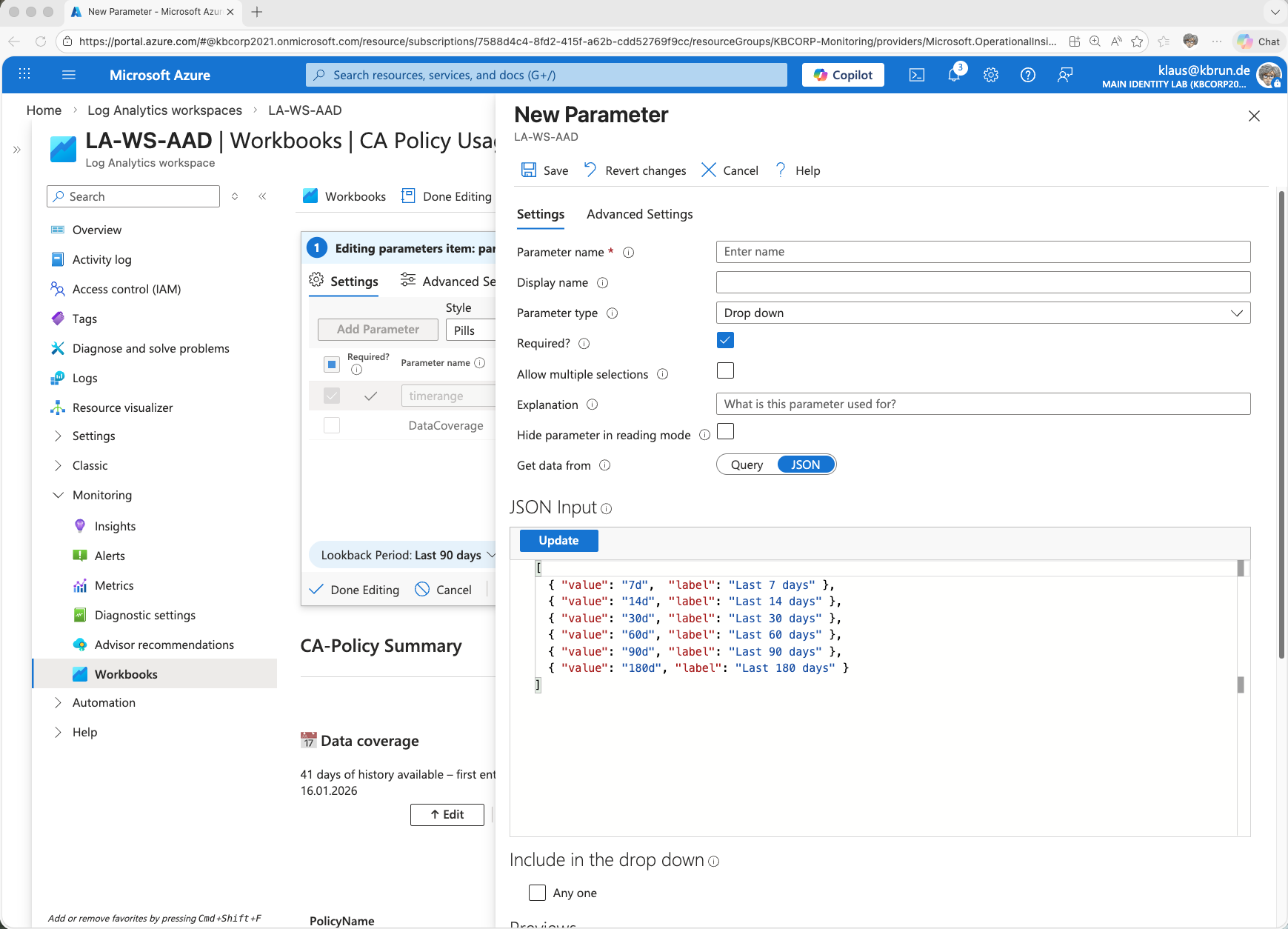
The same approach applies to the parameter DataCoverage. This is also a parameter, but of type Text. The displayed content is calculated using its own KQL statement.
This allows the workbook to dynamically determine how far back the available data actually goes. As a result, it is always visible which period real log data is available for, independent of the selected lookback value.
Especially if the retention period in the Log Analytics workspace has been changed or is not clearly known, this parameter provides quick and transparent visibility.
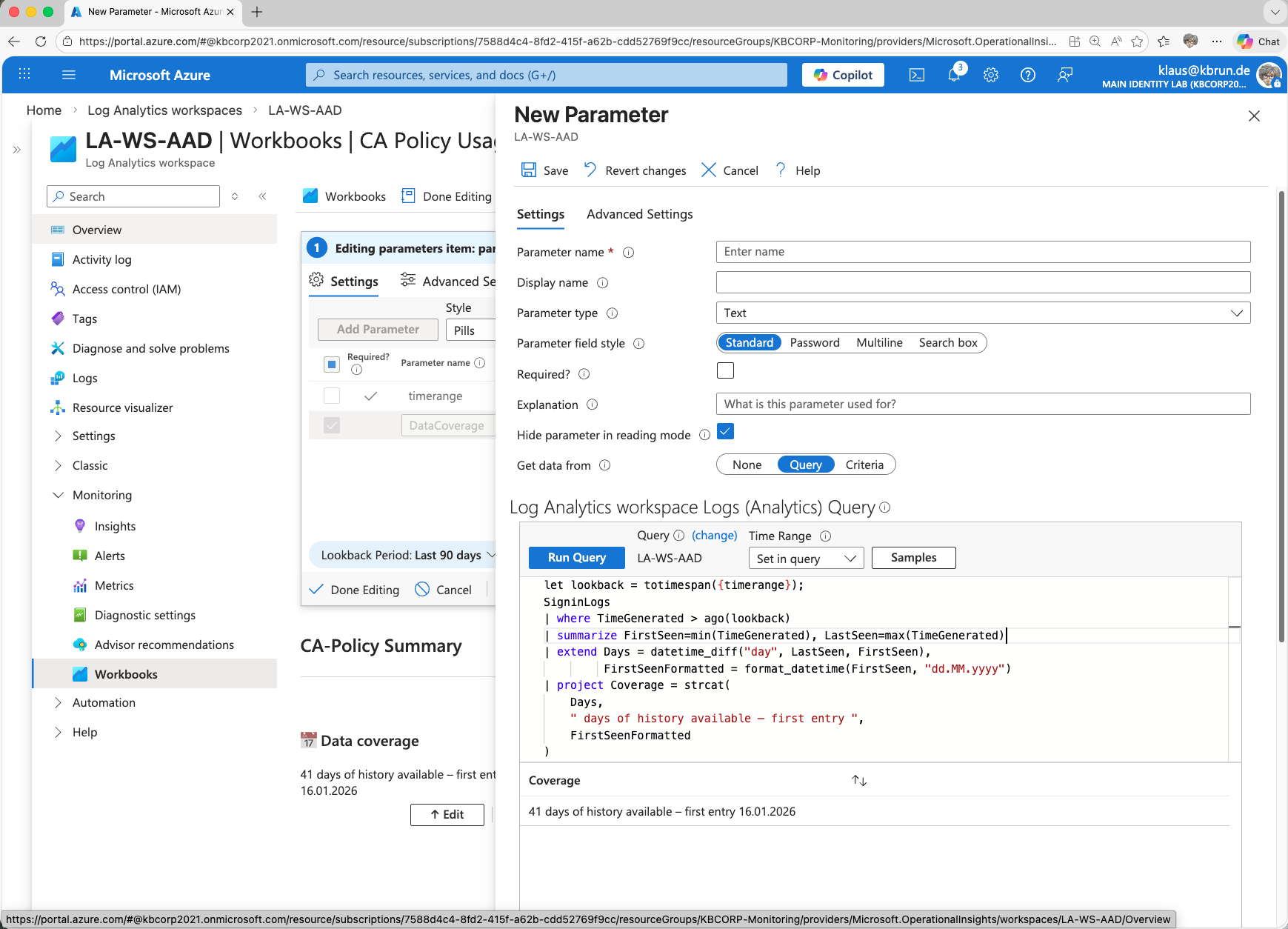
In the text element described above, the information is only calculated. It is displayed in a second text element placed directly below it in the view.
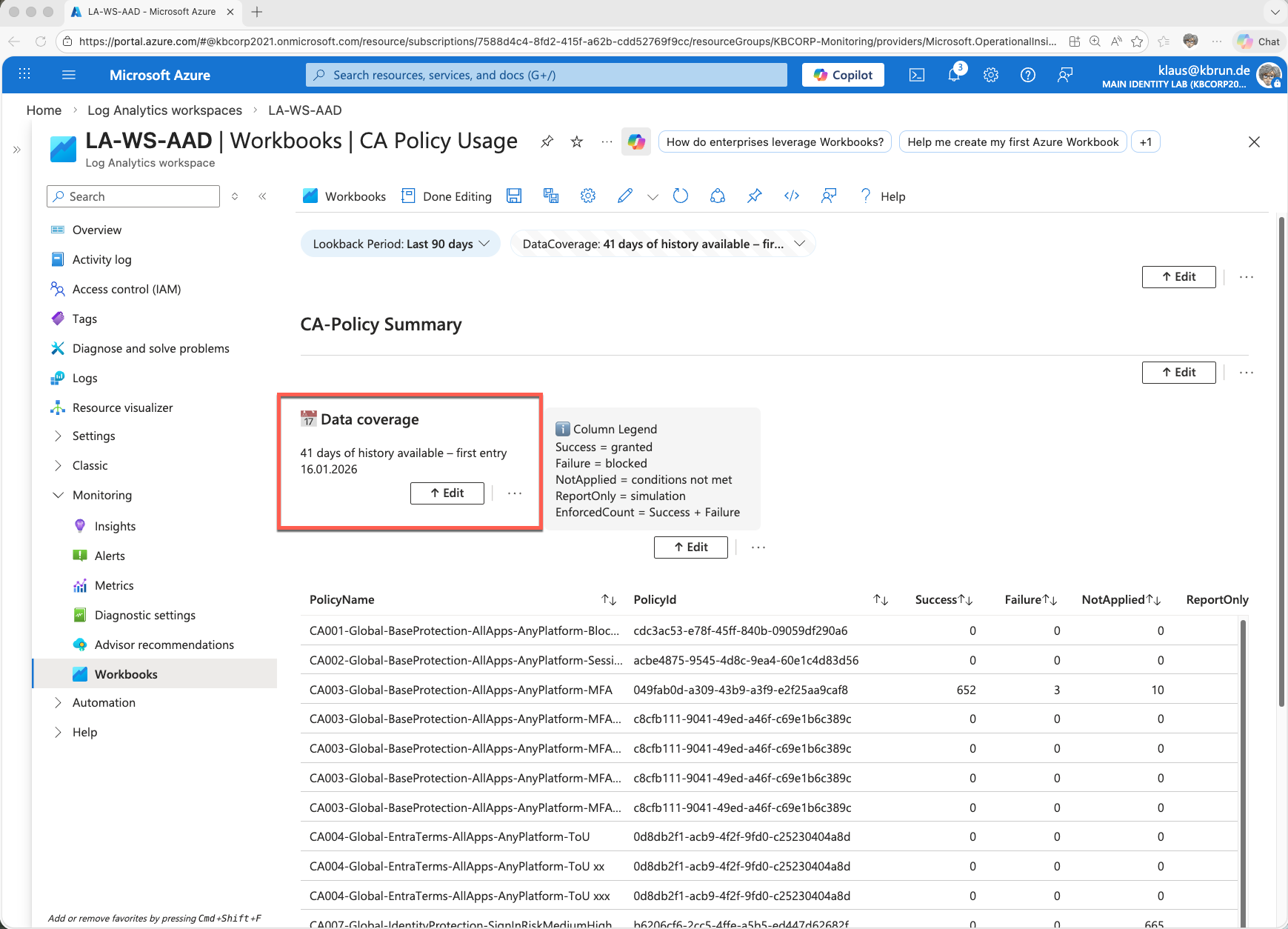
This second text field is much less complex. It simply references the previously calculated value from “DataCoverage” and displays it.
This example clearly shows that workbook elements do not operate in isolation. Parameters and queries can be reused across elements. In this case, the value calculated in the first step (“DataCoverage”) is reused and displayed in a separate element.
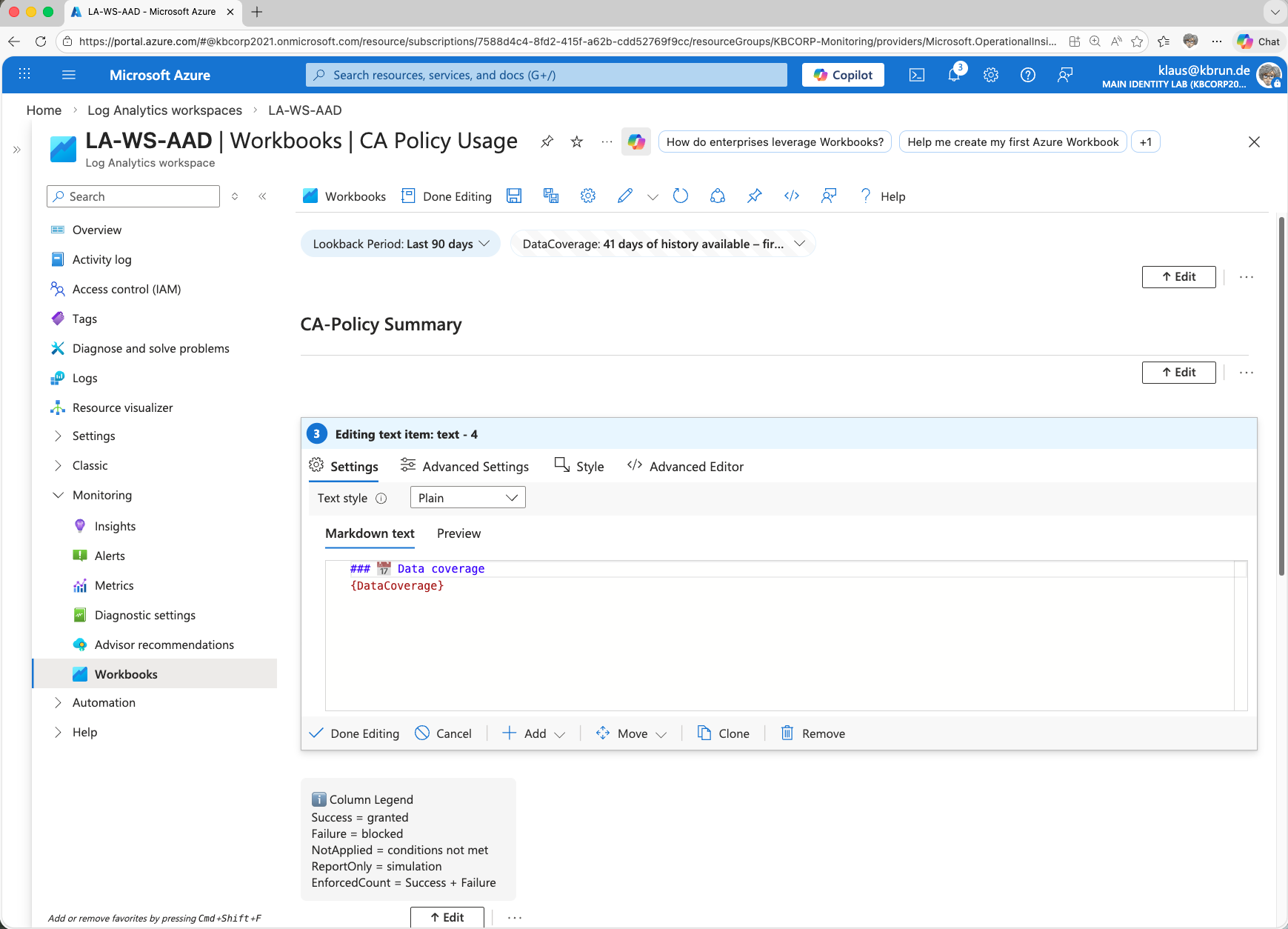
Normally, workbook elements are displayed one below the other. An exception is the element type “Group”.
Both the Legend and Data Coverage are part of such a Group in this example. This allows the elements to be placed side by side and arranged in a clean layout.
If you want to implement this layout, select the element type Group when adding a new element and then add the desired elements within that group.
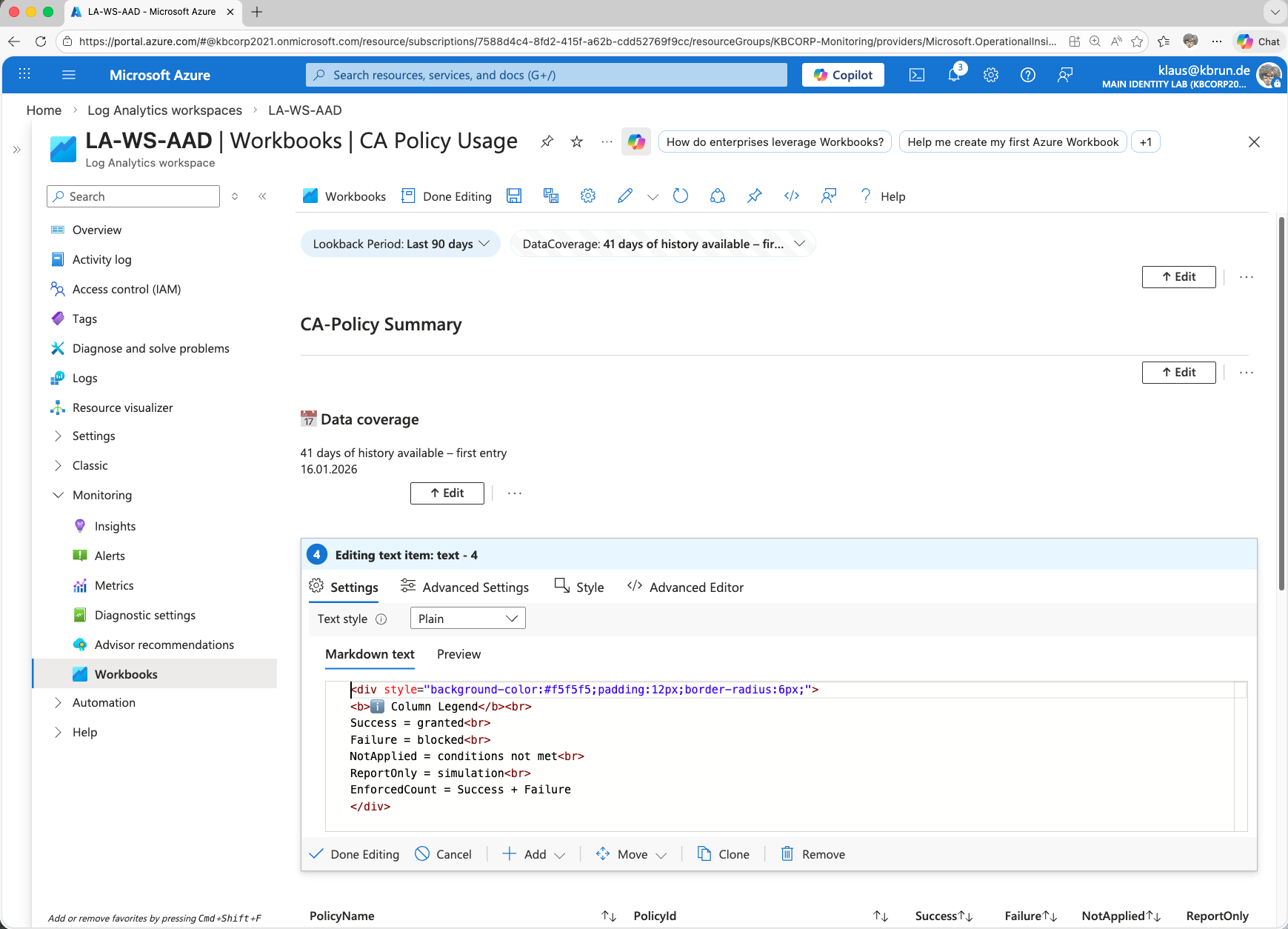
If we look at the legend using Edit, we simply find static text.
The actual main work is performed by a KQL query. It generates the columns in which we see the evaluations of the individual Conditional Access policies.
The core elements of the query are as follows:
First, we retrieve the selected time range using the parameter timerange, which was defined earlier in the dropdown field. This value is used as the lookback period in the query and determines how far back the analysis should go.
let lookback = totimespan({timerange});
Next, we determine the total number of policy evaluations:
let totalEvaluations =
toscalar(
SigninLogs
| where TimeGenerated > ago(lookback)
| mv-expand CAP = ConditionalAccessPolicies
| where isnotempty(tostring(CAP.id))
| count
);
Then comes the main query:
SigninLogs
| where TimeGenerated > ago(lookback)
| mv-expand CAP = ConditionalAccessPolicies
First, the sign-in logs are filtered for the selected time range. Afterwards, the contained Conditional Access information is normalized: for each sign-in, one row is created per evaluated policy.
| extend
PolicyName = tostring(CAP.displayName),
PolicyId = tostring(CAP.id),
CAResult = tostring(CAP.result)
The CAP object is of type dynamic. In order to aggregate the contained information later, we extract the relevant properties (name, ID, and result) and convert them into strings.
The PolicyId is especially important because it is unique. The policy name alone is not sufficient, since policies may have been deleted and recreated with the same name. The ID remains the reliable reference.
Using summarize, we then count the results:
| summarize
Success = countif(CAResult == "success"),
Failure = countif(CAResult == "failure"),
NotApplied = countif(CAResult == "notApplied"),
ReportOnly = countif(CAResult startswith "reportOnly")
by PolicyName, PolicyId
The calculated values are written directly into the corresponding columns of the displayed table.
EnforcedCount shows how often a policy actually took effect, meaning how often it enforced a decision (Success or Failure).
In this example, this is more of a supplementary value: it is created through a simple addition of Success and Failure and mainly serves as a quick indicator.
| extend EnforcedCount = Success + Failure
The KQL sequence therefore transforms raw sign-in data into an analyzable statistic for Conditional Access policies.
First, the sign-in logs are filtered for the selected time range. Afterwards, the CA information is normalized: for each sign-in, one row is created per evaluated policy.
Summary
You now have a clear overview of how your Conditional Access policies are actually being applied in your tenant.
Policies that never trigger, rarely apply, or only exist in ReportOnly mode become visible immediately. This makes it much easier to identify legacy configurations, redundant rules, or simply policies that no longer serve a real purpose.
Conditional Access tends to grow over time. New requirements lead to new policies, but rarely are old ones reviewed or cleaned up. A structured overview like this turns raw log data into actionable governance insight.
Other issues, such as duplicate or overlapping CA policies or users not covered by Conditional Access policies at all, can be identified using the Conditional Access Optimization Agent. I recently wrote an article about this as well:
Conditional Access Meets AI
Deutsche Version
Allgemeines
In Entra findest Du einige Workbooks mit hilfreichen Informationen zum Zustand Deines Tenants. Diese befinden sich im Entra Admin Center im Bereich Monitoring & Health, direkt unter Workbooks.
Dem Thema Conditional Access ist dabei eine eigene Rubrik gewidmet. Wen wunderts, CA-Policies gehören zu den sicherheitskritischsten Konfigurationen im Tenant.
Die vorhandenen Workbooks im Bereich Insights betrachten jedoch einzelne Perspektiven: Benutzer, Zielressourcen oder identifizierte Risiken.
Dabei ist mir im Rahmen meiner Entra-Housekeeping-Aktivitäten aufgefallen, dass es kein zentrales Workbook gibt, das zeigt, welche Policy erfolgreich angewendet wurde, welche blockiert hat und welche möglicherweise nie greift und damit potenziell überflüssig ist.
Genau das möchte ich mit diesem Beitrag ändern. Wir erstellen ein einfaches Workbook, das diese Übersicht liefert und das Du anschließend nach deinen eigenen Anforderungen erweitern kannst. Nebenbei besprechen wir einige wichtige Elemente für die Erstellung von Workbooks
Wenn Dich die einzelnen Schritte nicht im Detail interessieren, kannst Du das JSON-Workbook-Template auch direkt herunterladen und sofort ausprobieren. Erstelle hierfür einfach ein leeres Workbook und importiere den Inhalt aus der JSON-Datei.
Ein Workbook bietet sehr viele Möglichkeiten zur Gestaltung einzelner Elemente. Entsprechend umfangreich sind auch die verfügbaren Parameter und Konfigurationsoptionen. Es wäre weder sinnvoll noch zielführend, hier jedes Detail im Einzelnen zu erläutern. Das kann Microsoft in MS Learn viel besser.
Wir konzentrieren uns im Folgenden auf die wesentlichen Elemente und deren wichtigste Eigenschaften.
Wenn Du das Workbook Schritt für Schritt selbst aufbauen möchtest, auch um ein besseres Verständnis für die Funktionsweise zu entwickeln, empfehle ich Dir ein Workbook zu erstellen und anschließend das oben bereits erwähnte JSON Template zu importieren.
So erhältst Du das vollständig konfigurierte Workbook, kannst es editieren und Dir alle Parameter und deren Eigenschaften im Detail anschauen und parallel dazu Dein eigenes Workbook mit denselben Informationen nachbauen und besser nachvollziehen.
Voraussetzung: Logs in Log Analytics
Wenn Du Auswertungen über einen längeren Zeitraum machen möchtest, müssen die Log-Daten in einem Log Analytics Workspace liegen.
Standardmäßig ist das nicht so. Entra speichert Sign-in- und Audit-Logs (je nach Lizenz) nur für einen begrenzten Zeitraum (meist bis zu 30 Tage) direkt in Entra ID.
Wenn Du also weiter zurückschauen möchtest, und genau das brauchen wir für Housekeeping, benötigst Du einen Ort, an dem die Logs dauerhaft gespeichert werden.
Ein Log Analytics Workspace ist genau das: ein zentraler Speicher für Deine Logs. Zusätzlich bekommst Du dort die Möglichkeit, mit KQL gezielt Abfragen zu bauen und die Daten auszuwerten.
Ohne Log Analytics kannst Du nur sehr eingeschränkt historisch analysieren. Und mit Log Analytics wird daraus eine echte Datenbasis für Governance-Entscheidungen.
Wie du diesen einrichtest und wie die Logdaten dorthin gelangen habe ich vor längerer Zeit in einem Beitrag beschrieben. Schau am besten hier: Zero Trust Monitoring
Die obige Abbildung zeigt das Workbook mit seinen einzelnen Bereichen:
Zeitraum auswählen
Hier kannst Du den gewünschten Zeitraum einstellen. In der Dropdown-Liste gehe ich bis zu 180 Tage zurück, vorausgesetzt, es liegen für diesen Zeitraum auch Daten vor (Retention / Aufbewahrungszeit).Tatsächliche Datenabdeckung
Dieser Bereich zeigt an, wie weit die vorhandenen Daten tatsächlich zurückreichen. Das ist besonders hilfreich, wenn Du die eingestellte Retention im Log Analytics Workspace nicht genau kennst. In meiner Abbildung sind es beispielsweise 41 Tage. Das liegt daran, dass ich die Retention im Log Analytics Workspace erst vor 11 Tagen erhöht habe. Entsprechend stehen aktuell noch keine älteren Daten zur Verfügung.Legende
Eine kleine Legende erklärt die Bedeutung der einzelnen Spalten im Workbook.Policy-Informationen
Hier siehst Du die eigentlichen Auswertungen zu den Conditional-Access-Policies. In meiner Testumgebung erscheinen einige Policies doppelt. Das ist kein Fehler im Workbook. Der Grund ist, dass ich für einige Tests zu Backup/Recovery von CA-Policies mehrere gelöscht und anschließend wieder importiert habe. Dadurch existieren im Log Analytics Workspace historische Logdaten zu unterschiedlichen Policy-Ids, auch wenn der Name identisch ist. Unter normalen Bedingungen in einer produktiven Umgebung tritt dieses Verhalten nicht auf.
Workbook Elemente im Detail
Wenn Du ein neues, leeres Workbook erstellt hast, ist der erste Schritt, ein neues Element hinzuzufügen. In unserem Fall benötigen wir einen Parameter, der später quasi als Variable im eigentlichen KQL-Query verwendet wird.
Workbooks bestehen aus unterschiedlichen Elementtypen, zum Beispiel Text, Abfragen oder Parametern. Für unseren Anwendungsfall wählen wir den Typ Parameter, diesen können wir später im KQL-Query referenzieren .
Der Parameter Lookback Period liefert uns den Zeitraum (z. B. 30, 90 oder 180 Tage), den wir im Query über {timerange} weiterverwenden. Damit bleibt das Workbook flexibel, ohne dass wir das Query selbst anpassen müssen.
Die fertiggestellte Dropdown Box sieht in ihrer Definition dann wie folgt aus
Ähnlich verhält es sich mit dem Parameter DataCoverage. Hierbei handelt es sich ebenfalls um einen Parameter, allerdings vom Typ Text. Der angezeigte Inhalt wird über ein eigenes KQL-Statement ermittelt.
So wird im Workbook dynamisch berechnet, wie weit die tatsächlich vorhandenen Daten zurückreichen. Dadurch ist in der Ansicht jederzeit ersichtlich, über welchen Zeitraum reale Log-Daten vorliegen, unabhängig davon, welcher Lookback-Wert ausgewählt wurde.
Gerade wenn die Retention im Log Analytics Workspace geändert wurde oder nicht genau bekannt ist, liefert dieser Parameter eine schnelle und transparente Orientierung.
Im oben beschriebenen Textelement werden die Informationen lediglich ermittelt. Angezeigt werden sie in einem zweiten Textelement, das in der Ansicht direkt darunter platziert ist
Dieses zweite Textfeld ist deutlich weniger komplex. Es greift lediglich auf den zuvor berechneten Wert aus DataCoverage zu und stellt ihn dar.
An diesem Beispiel wird gut sichtbar, dass die einzelnen Elemente eines Workbooks nicht isoliert voneinander arbeiten. Parameter und Abfragen können übergreifend genutzt werden. In diesem Fall wird der im ersten Schritt ermittelte Wert „DataCoverage“ in einem separaten Element wiederverwendet und angezeigt.
Normalerweise werden die einzelnen Elemente in einem Workbook untereinander dargestellt. Eine Ausnahme bildet jedoch das Element Group.
Sowohl die Legende als auch Data Coverage sind in diesem Fall Teil einer solchen Group. Dadurch lassen sich die Elemente einfach nebeneinander platzieren und übersichtlich anordnen.
Wenn du das so umsetzen möchtest, wählst Du beim Hinzufügen eines neuen Elements den Typ Group aus und fügst die gewünschten Elemente innerhalb dieser Gruppe hinzu.
Schauen wir uns mit Edit den Inhalt der Legende an, so ist hier einfacher statischer Text zu finden
Die eigentliche Hauptarbeit übernimmt ein KQL-Query. Es erzeugt die Spalten, in denen wir die Auswertungen zu den einzelnen Conditional-Access-Policies sehen.
Den Kern der Abfrage bilden dabei folgende Elemente:
Zunächst holen wir uns den gewünschten Zeitraum über den Parameter timerange, der zuvor im Dropdown-Feld definiert wurde. Dieser Wert wird als Lookback in der Abfrage verwendet und bestimmt, wie weit die Analyse zurückreichen soll.
let lookback = totimespan({timerange});
Dann ermitteln wir die Gesamtanzahl aller Policies
let totalEvaluations =
toscalar(
SigninLogs
| where TimeGenerated > ago(lookback)
| mv-expand CAP = ConditionalAccessPolicies
| where isnotempty(tostring(CAP.id))
| count
);
Dann kommt die Hauptabfrage:
SigninLogs
| where TimeGenerated > ago(lookback)
| mv-expand CAP = ConditionalAccessPolicies
Zunächst werden die Sign-in-Logs auf den gewählten Zeitraum gefiltert. Anschließend werden die enthaltenen Conditional-Access-Informationen normalisiert: Für jeden Sign-in entsteht eine eigene Zeile pro ausgewerteter Policy.
| extend
PolicyName = tostring(CAP.displayName),
PolicyId = tostring(CAP.id),
CAResult = tostring(CAP.result)
Das CAP-Objekt ist vom Typ dynamic. Um die enthaltenen Informationen später aggregieren zu können, extrahieren wir die relevanten Eigenschaften, Name, ID und Ergebnis und wandeln sie in Strings um.
Die PolicyId ist dabei besonders wichtig, da sie eindeutig ist. Der Policy-Name allein reicht nicht aus, da Policies gelöscht und mit identischem Namen neu erstellt worden sein können. Die ID bleibt hingegen die verlässliche Referenz.
Über summarize zählen wir dann die Ergebnisse
| summarize
Success = countif(CAResult == "success"),
Failure = countif(CAResult == "failure"),
NotApplied = countif(CAResult == "notApplied"),
ReportOnly = countif(CAResult startswith "reportOnly")
by PolicyName, PolicyId
Die ermittelten Werte werden direkt in die entsprechenden Spalten der angezeigten Tabelle geschrieben.
EnforcedCount zeigt, wie oft eine Policy tatsächlich gegriffen hat, also wie häufig sie eine Entscheidung erzwungen hat (Success oder Failure).
In diesem Beispiel ist das jedoch eher ergänzende Information: Der Wert entsteht durch eine einfache Addition von Success und Failure und dient vor allem der schnellen Einordnung.
| extend EnforcedCount = Success + Failure
Die KQL-Sequenz transformiert somit rohe Sign-in-Daten in eine auswertbare Statistik zu den Conditional-Access-Policies.
Zusammenfassung
Du erhältst mit diesem Workbook eine Übersicht, wie deine Conditional-Access-Policies tatsächlich im Tenant angewendet werden.
Policies, die nie greifen, nur selten angewendet werden oder dauerhaft im ReportOnly-Modus laufen, werden sofort sichtbar. Dadurch lassen sich Altlasten, redundante Regeln oder schlicht überflüssige Policies schnell identifizieren.
Conditional Access wächst über die Zeit. Neue Anforderungen führen zu neuen Policies, alte werden jedoch selten überprüft oder bereinigt. Eine strukturierte Übersicht wie diese macht aus reinen Log-Daten konkrete Governance-Erkenntnisse.
Weitere Themen wie doppelte oder überlappende CA-Policies oder Benutzer, die nicht im Scope von Conditional Access liegen, kannst Du mit dem Conditional Access Optimization Agent identifizieren. Dazu habe ich vor kurzem bereits einen Beitrag veröffentlicht:
Conditional Access Meets AI
Cover image: Designed by vectorjuice / Freepik
